

AIBrain Talk: AI and Human Safety
On August 17, 2016 Steve Omohundro spoke to the “Million AI Startups” group about “AI and Human Safety”:
https://www.meetup.com/Million-AI-Startups/events/232809489/
AI and robotics will create $50 trillion of value over the next 10 years according to McKinsey. This is causing their rapid development but six recent events show the need to be careful as they are integrated into human society. In the past few weeks we’ve seen three Tesla autopilot crashes, the Dallas police using a robot to kill a suspect, a Stanford Shopping Center security robot running over a small child, and the first “Decentralized Autonomous Organization” losing $56 million due to a bug in a smart contract. As we move forward with these technologies, we will need to incorporate human values and new principles of security so that their human benefits can be fully realized.
Medium: 5 Transcripts of Older AI Talks
A huge “Thank You!” to @Jeriaska for transcribing and publishing these transcripts to Medium:
“The Nature of Self-Improving Artificial Intelligence”, October 27, 2007
“Self-Improving AI: The Future of Computation”, November 1, 2007
“Self-Improving AI: Social Consequences”, November 1, 2007
TEDX Talk: What’s Happening With Artificial Intelligence?
The TED conference, started in 1984, has become the standard bearer for hosting insightful talks on a variety of important subjects. They have made videos of over 1,900 of these talks freely available online and they have been watched more than a billion times! In 2009 they extended the concept to “TEDx Talks” in the same format but hosted by independent organizations all over the world.
On January 6, 2016 Mountain View High School hosted a TEDx event on the theme of “Next Generation: What Will It Look Like?”. They invited both students from the school and external speakers to present. I spoke on “What’s Happening With Artificial Intelligence?”. A video of the talk is available here:
and the slides are available here:
TEDX – What’s Happening With Artificial Intelligence ?
I talked about the multi-billion dollar investments in AI and robotics being made by all the top technology companies and the 50 trillion dollars of value they are expected to create over the next 10 years. The human brain has 86 billion neurons wired up according to the “connectome”. In 1957 Frank Rosenblatt created a teachable artificial neuron called a “Perceptron”. Three-layer networks of artificial neurons were common in 1986 and much more complex “Deep Learning Neural Networks” were being studied by 2007. These networks started winning a variety of AI competitions besting other approaches and often beating human performance. These systems are starting to have a big effect on robot manufacturing, self-driving cars, drones, and other emerging technologies. Deep learning systems which create images, music, and sentences are rapidly becoming more common. There are safety issues but several institutes are now working to address the problems. There are many sources of excellent free resources for learning and the future looks very bright!
Eileen Clegg did wonderful real time visual representations of the talks as they were being given. Here is her drawing of my talk:
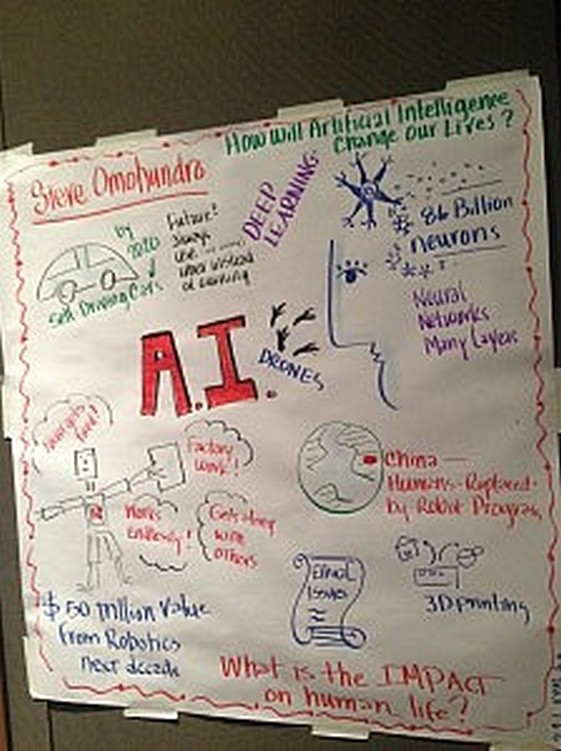
Edge Essay: Deep Learning, Semantics, and Society
Each year Edge, the online “Reality Club”, asks a number of thinkers a question and they publish the short essay answers. This year the question was “What do you consider the most interesting recent scientific news? What makes it important?” The responses are here:
My own essay on “Deep Learning, Semantics, And Society” is here:
http://edge.org/response-detail/26689
The Basic AI Drives in One Sentence
“If your goal is to play good chess, and being turned off means that you play no chess, then you should try to keep yourself from being turned off.”
So chess robots should be self-protective. The logic is not complicated. My 9 year old nephew has no trouble understanding it and explaining it to his friends. And yet very smart people continue to argue against this idea vociferously. When I first started speaking and writing about this issue, I expected people to respond with “Oh my goodness, yes, that’s an issue, let’s figure out how to design safe systems that deal with that appropriately.”
But you can see videos of some of my older lectures where audience members stand up, red in the face, screaming things like “economics doesn’t describe intelligence”. Others have argued that it is due to an insufficiently “feminine” view of intelligence. Others say that this is “anthropomorphizing” or “only applies to evolved systems” or “only applies to systems built on logic” or “only applies to emotional systems”. Hundreds of vitriolic posts on discussion forums have argued with this simple insight. And there have even been arguments that autonomy is just a “myth”.
Here are one-sentence versions of some of the other drives:
“If your goal is to play good chess and having more resources helps you play better chess, then you should try to get more resources.”
“If your goal is to play good chess and changing that goal means you will play less chess, then you should resist changing that goal.”
“If your goal is to play good chess and you can play more chess by making copies of yourself, then you should try to make copies of yourself.”
“If your goal is to play good chess and you can play better if you improve your algorithms, then you should try to improve your algorithms.”
In a widely-read paper, I called these the “Basic AI Drives”. But they apply to any system which is trying to accomplish something including biological minds, committees, companies, insect hives, bacteria, etc. It’s especially easy to see why evolution rewards reproduction but these drives are not restricted to systems that have evolved.
I used the goal of “play good chess” because it’s simple to understand and seems harmless. But the same logic applies to almost any simple goal. In the papers, I describe some “perverse” goals (like the goal of “turning yourself off”) where they don’t apply but these aren’t relevant for most real systems.
Does this mean that we shouldn’t build autonomous systems? Of course not! It just means that creating intelligence is only part of the problem. We also need to create goals which are aligned with human values. Is that impossibly difficult? I’ve seen no evidence that it’s extremely hard, but simple proposals tend to create complex incentives which lead to the same kinds of behavior in a more complicated form.
What we really need is a rigorous science of the behavior of goal-driven systems and an engineering discipline for the design of safe goals. In a recent paper, Tsvi Benson-Tilsen and Nate Soares analyzed a formal model of these phenomena which I think is a great start!
Robotics, Artificial Intelligence and the Law Meetup: Regulating AI and Robotics

On Wednesday, September 23, 2015 Steve Omohundro will present a talk on “Regulating AI and Robotics” to the “Robotics, Artificial Intelligence, and the Law” Meetup Group led by Stephen Wu, Silicon Valley Law Group:
http://www.meetup.com/Robotics-Artificial-Intelligence-and-the-Law/events/225080409/
Here are the slides, here is the audio of the talk, and here is the description:
We are delighted to have Steve Omohundro, Ph.D. present at our Meetup this month. This is a Meetup of the Artificial Intelligence and Robotics Interest Group of the Santa Clara County Bar Association High Technology Law Section, and the Artificial Intelligence Committee of the American Bar Association Section of Science & Technology Law.
About our speaker:
Steve Omohundro has been a scientist, professor, author, software architect, and entrepreneur doing research that explores the interface between mind and matter. He has degrees in Physics and Mathematics from Stanford and a Ph.D. in Physics from U.C. Berkeley. He was a computer science professor at the University of Illinois and cofounded the Center for Complex Systems Research. He published the book “Geometric Perturbation Theory in Physics”, designed the programming languages StarLisp and Sather, wrote the 3D graphics system for Mathematica, and built systems which learn to read lips, control robots, and induce grammars. He is president of both Possibility Research and Self-Aware Systems, a think tank working to ensure that intelligent technologies have a positive impact. His work on positive intelligent technologies was featured in James Barrat’s book “Our Final Invention” and has generated international interest. He serves on the advisory boards of the Cryptocurrency Research Group, the Institute for Blockchain Studies, Design Economics, Dfinity, Cognitalk, and is the chair of the Silicon Valley ACM Artificial Intelligence SIG.
See his TED talk here:
https://www.youtube.com/watch?v=1O2l1dc_ohA
Intro to this month’s topic:
Robot manufacturing, self-driving cars, 3-d printed houses, agricultural drones, etc. are poised to dramatically improve human life and eliminate drudgery. McKinsey predicts that AI and Robotics will create $50 trillion in value over the next 10 years. But these systems also create many new regulatory challenges. We will need new technological and legal governance strategies to receive the benefits without causing harm. When a self-driving car kills someone, who is liable? If I create a harmful robot, I am liable, but if I create an AI system which creates a harmful robot, am I still liable? Already humans are avoiding liability by using automated systems for price fixing, insider trading, discrimination, downloading illegal content, and making illegal drug purchases. Many robotic systems can easily be made anonymous but anonymous drones, self-driving cars, and online bots can be used for extortion, assassination, blackmail, theft, terror, etc. And intelligent systems can behave in unpredictable ways. Recent “deep learning” neural networks create models with huge blindspots. The behavior of advanced autonomous systems will be even less predictable by their creators. Rational systems with simplistic goals exhibit “rational drives” toward self-preservation, resource acquisition, replication, and self-improvement. What is the liability for creating harmful systems? We need to develop new technologies to reliably control these systems and a new regulatory regime to incentivize safe and beneficial behavior. We describe Ethereum’s “Smart Contracts” as a possible technological component. But many additional new ideas are clearly needed.
A dial-in number will be provided no later than the morning of the talk.
Slides: Right before the talk, a link to see any slides the speaker wants to present will be provided. (There may or may not be slides.) This link will expire at the end of the talk, but we will distribute a pdf of the slides by download afterwards.
Please RSVP and let us know by a comment if you are planning to attend in person.
ACGSV Event: Artificial Intelligence – Potential and Risks
On Thursday, September 24, 2015 at 6:00, ACG Silicon Valley will host a discussion of “Artificial Intelligence – Potential and Risks” moderated by Mike Malone and with panelists Richard Socher, Steve Omohundro, Moshe Looks, and Douglas Stay:
http://acgsv.org/event/artificial-intelligence-potential-and-risks/
Here’s a video of the highlights of the discussion.
Their description of the evening:
Why did Peter Norvig, Elon Musk, Steve Wozniak, and Stephen Hawking all sign a letter about the “remarkable successes in … speech recognition, image classification, autonomous vehicles, machine translation, legged locomotion, and question-answering systems?” Because “we cannot predict what we might achieve when [human] intelligence is magnified by the tools Artificial Intelligence may provide.” Deep learning and Convolutional Neural Networks are revolutionizing search, natural language processing and computer vision. Join us to learn what every executive needs to know about Artificial Intelligence.

Singularity Article: Designing AI Infrastructures that Sustain the Human Race
On September 16, 2015, Daniel Faggella posted this article on the Singularity Weblog summarizing our discussion of ways to create a positive AI infrastructure:
The original interview can be heard as Episode #92 of the TechEmergence podcast:
We talked about the 3 waves of AI and Robotics: economic, military, and society. Safety issues and the historical lessons from nuclear weapons and energy. And the “Safe-AI Scaffolding Strategy” and a safety infrastructure. He created this great graphic to illustrate it:

RoboPsych Interview about the TV Show “Humans”
On September 17, 2015, the psychologist Tom Guarriello interviewed me for his “RoboPsych” podcast:
http://www.robopsych.com/robopsychpodcast/8182015
We talked about the newly-emerging psychology of humans interacting with robots and AI. And, *SPOILER WARNING*, we discussed the first season of the excellent recent AMC/BBC show “Humans”.
The flood of recent movies and TV shows exploring the impact of robots and AI. Early shows like Terminator and Robocop focused on “Us vs. Them”. More recent shows like “Her” and “Humans” explore subtler aspects of the interaction.
The archetype of the “Out of Control Creation”. The Sorcerer’s Apprentice. Stories of Genies giving three wishes but with unintended outcomes. King Midas. The “Uh-Oh!”. Even if you get what you think you want, it may not be what you really want. Adam and Eve as the first out of control creation story. We ourselves are out of control. Fear of the other is a projection of our own darker inner drives.
“Humans” takes place in the present but with a more advanced “Synth” android robot technology. Family dynamics with Synths. The little girl sees the synth as a mother figure. The mother is jealous of the synth. The teenage boy is sexually attracted to the synth. Synths as a memory prosthetic. Synths with consciousness. Synths with subpersonalities.
How close is today’s technology to anything like this? Economic drivers for building AIs that recognize human emotional facial and vocal expressions. Recent Microsoft AI to judge the humor of New Yorker cartoons. Artificial empathy. Jibo and Pepper. Things are moving extremely rapidly. McKinsey estimates $50 trillion dollars of impact in the next 10 years. Deep Learning is used for many functions. Baidu using it for Chinese. If understanding human emotions has economic value, it will soon be in the marketplace.
Humans are not good at determining how emotionally intelligent an entity is. Eliza was an early 1960’s AI system. It used simple pattern matching to mimic a Rogerian therapist. Yet people spent hours talking to it! Deep tendency for people to form attachments to objects. People naming their Roombas. Soldiers attached to their IED-detecting robots. Synths can behave more maturely than humans! Non-Violent Communication.
Synths in the service of marketing for a brand? “Hidden Persuaders” and sexuality in advertising. Brands adopt the “Jester” archetype when they ride on deep primal urges like sexuality. Japan and virtual girlfriends. Japan’s relationship to robots. Robots for elder-care. Belief in robot euthanasia hoax. The uncanny valley. Elder’s experience with robotic companions. Robot pets. Tamagotchi. Sony stopping Aibo robot dog support. Kids don’t learn how to handwrite anymore. Horse riding becoming less common. Future shock. Visions of the future from the past. Approach/Avoidance conflicts.
Creators of these systems want them to have intelligence and creativity but they also want to retain control of them. Are they alive, what rights do they have? Building in safeguards. How can we have confidence that these systems won’t run amok? In Humans, the Synths exhibit ambiguity about their own consciousness. Give the code for consciousness to a human for safekeeping. But Niska secretly keeps her own copy and may want to spread it in Season Two! The Synth’s experiences affect their behavior.
What happens when a system can change its own structure? What is the nature of goals and behavior? Unintended consequences. Basic Rational or AI Drives for self-preservation, resource acquisition, replication, efficiency. We need to be careful as we build systems with their own intentions. Deep mind system that adapts to play video games. When will systems start exhibiting unexpected behavior? Robot “Fail” videos. “Whistling past the graveyard?” When we see goofy behavior, it assuages our fear: “Nothing to see here. Move along.”
Robot soldiers, South Korean autonomous gun turret, drones, etc. “How can we be very sure that these systems are safe?” A conservative strategy: The “Safe-AI Scaffolding Strategy”. Regardless of how smart they are, these systems have to obey the laws of mathematics and physics. Create mathematical proofs of properties of behavior. But proofs are hard. Need AI systems to help us establish safety guarantees. Start with very constrained systems like biohazard labs. Err on the side of caution because we are toying with very powerful forces here.
Psychoanalytic aspects of the Beatrice Synth. Suicidal synths? Humanity vs. being human. Ending of the first season with an anti-synth “We are human” protest and the conscious synths escape by blending in with the humans.
China is rapidly automating
Many in the U.S. have viewed cheap labor as China’s primary strength. But Chinese labor costs have nearly quadrupled over the past 10 years:

Recent studies have shown that it’s now just as cheap to manufacture in the U.S. as in China. This is one motivating force behind China’s rapid adoption of automation.
The Changying Precision Technology Company just set up the first unmanned factory in Dongguan city. 60 robots now perform tasks that required 650 workers just a few months ago. The defect rate has dropped by a factor of 5 and productivity has increased by almost a factor of 3. The city of Dongguan plans to complete 1,500 more “Robot replace human” factory transformations by 2016.
The use of robots in Chinese factories has been growing at a 40% annual rate and China is expected to have more manufacturing robots than any other country by 2017. The rapidity of adoption is shown in the following chart:

There are now 420 robot companies in China! The Chinese Deputy Minister of Industry Su Bo has described a robot technology roadmap for China to become a dominant robotics provider by 2020.
Robin Li Yanhong, the CEO of Baidu also wants to make China the world leader in AI. He has proposed the “China Brain” project as a massive state-level initiative “comparable to how the Apollo space programme was undertaken by the United States to land the first humans on the moon in 1969.” Last year Baidu hired Stanford and Google researcher Andrew Ng who says: “Whoever wins artificial intelligence will win the internet in China and around the world. Baidu has the best shot to make it work.”
McKinsey: $50 trillion of value to be created by AI and Robotics through 2025
- Automation of knowledge work: $5.2-6.7 trillion
- Internet of things: $2.7-6.2 trillion
- Advanced robotics: $1.7-4.5 trillion
- Autonomous and near-autonomous vehicles: $.2-1.9 trillion
- 3D printing: $.2-.6 trillion
- Total impact to 2025: $50-99.5 trillion
Logic for Safety
Many people seem to be misunderstanding the nature of mathematical proof in discussions of AI and software correctness, security, and safety. In this post, I’ll describe some of the background and context for this.
Almost every aspect of logic and mathematical proof has its origins in human language which emerged about 100,000 years ago. 2500 years ago, Aristotle and Euclid began the process of making the natural language rules precise. Modern logic began in 1677 when Leibniz tried to create a “calculus ratiocinator” to mechanically check precise arguments. The job was finished by Frege, Cantor, Zermelo, and Fraenkel in 1922 when they created a precise logical system capable of representing every mathematical argument and which stands as the foundation for mathematics today. Church and Turing extended this system to computation in 1936. Every precise argument in every computational, engineering, economic, scientific, and social discipline can be precisely represented in this formalism and efficiently checked on computer.
Some had hoped that beyond checking arguments, every statement might also be proven true or false in a mechanical way. These hopes were dashed by Goedel in 1931 when he published his incompleteness theorem showing that any logical system rich enough to represent the natural numbers must have statements which can neither be proven true nor false. In 1936 Turing found a simple computational variant now called “the halting problem” which showed there are some properties of some programs which cannot be proven or disproven.
But the Goedel statements and the uncomputable program properties are abstruse constructions that we never want to use in engineering! Engineering is about building devices we are confident will behave as we intend! Any decent programmer will have an argument as to why his program will work as intended. If he doesn’t have such an argument, he should be fired! If his argument is correct, it can be precisely represented in mathematical logic and checked by computer. The fact that this is not current standard practice is not due to limitations of logic or understanding but to sloppiness in the discipline and poor educational training. If engineers built bridges the way that we write programs, no one would dare drive over them. The abysmal state of today’s level of software correctness and security will likely be looked at with wonder and disgust by future generations.
Many countries are now building autonomous vehicles, autonomous drones, robot soldiers, autonomous trading systems, autonomous data gathering systems, etc. and the stakes are suddenly getting much bigger. If we want to be confident that these systems will not cause great harm, we need precise arguments to that effect. If you want to learn more about some of the extremely expensive and life harming consequences that have already happened due to ridiculous sloppiness in the design of our technology check out the beginning of a talk I gave at Stanford in 2007: https://www.youtube.com/watch?v=omsuTsOmvsc
Formal Methods for AI Safety
Future intelligent systems could cause great harm to humanity. Because of the large risks, if we are to responsibly build intelligent systems, they must not only be safe but we must be very convinced that they are safe. For example, an AI which is taught human morality by reinforcement learning might be safe, but it’s hard to see how we could become sufficiently convinced to responsibly deploy it.
Before deploying an advanced intelligent system, we should have a very convincing argument for its safety. If that argument is rigorously correct, then it is a mathematical proof. This is not a trivial endeavor! It’s just the only path that appears to be open to us.
The mathematical foundations of computing have been known since Church and Turing‘s work in 1936. Both created computational models which were simultaneously logical models about which theorems could be proved. Church created the lambda calculus which has since become the foundation for programming languages and Turing created the Turing machine which is the fundamental model for the analysis of algorithms.
Many systems for formal verification of properties of hardware and software have been constructed. John McCarthy created the programming language Lisp very explicitly from the lambda calculus. I studied with him in 1977 and did many projects proving properties of programs. de Bruijn‘s Automath system from 1967 was used to prove and verify many mathematical and computational properties.
There are now more than one hundred formal methods systems and they have been used to verify a wide variety of hardware systems, cryptographic protocols, compilers, and operating systems. After Intel had to write off $475 million due to the Pentium P5 floating point division bug, they started verifying their hardware using formal methods.
While these advances have been impressive, the world’s current technological infrastructure is woefully buggy, insecure, and sloppy. Computer science should be the most mathematical of all engineering disciplines with a precise stack of verified hardware, software, operating systems, and networks. Instead we have seething messes at all levels.
Building precise foundations will not be easy! I have been hard at work on new programming languages, specification languages, verification principles, and principles for creating specifications. Other groups have been proceeding in similar directions. Fortunately, intelligent systems are likely to be very helpful in this enterprise if we can build a trust foundation on top of which we can safely use them.
I have proposed the “Safe-AI Scaffolding Strategy” as a sequence of incremental steps toward the development of more powerful and flexible intelligent systems in which we have provable confidence of safety at each step. The systems in the early steps are highly constrained and so the safety properties are simpler to specify: only run on specified hardware, do not use more than the allocated resources, do not self-improve in uncontrolled ways, do not autonomously replicate, etc. Specifying the safety properties of more advanced systems which directly engage with the world is more challenging. I will present approaches for dealing with those issues at a later time.
IBM Research Video: AI, Robotics, and Smart Contracts
On March 26, 2015 Steve Omohundro spoke at the IBM Research Accelerated Discovery Lab in Almaden in the 2015 Distinguished Speaker Series about “AI, Robotics, and Smart Contracts”. There was a lively discussion about the positive and negative impacts of automation and where it is all going. The video is available here:
and the slides are here.
SRI Talk: AI, Robotics, and Smart Contracts
On Tuesday, April 21, 2015 at 4:00 PM Steve Omohundro will speak at the Artificial Intelligence Center at SRI in Menlo Park hosted by Richard Waldinger.
AI, Robotics, and Smart Contracts
| Steve Omohundro | Possibility Research and Self-Aware Systems | [Home Page] |
Notice: Hosted by Richard Waldinger
Date: Tuesday April 21st, 4pm
Location: EJ228 (SRI E building) (Directions)
Webex:
WebEx and VTC available upon request
|
|
Google, IBM, Microsoft, Apple, Facebook, Baidu, Foxconn, and others have recently made multi-billion dollar investments in artificial intelligence and robotics. Some of these investments are aimed at increasing productivity and enhancing coordination and cooperation. Others are aimed at creating strategic gains in competitive interactions. This is creating “arms races” in high-frequency trading, cyber warfare, drone warfare, stealth technology, surveillance systems, and missile warfare. Recently, Stephen Hawking, Elon Musk, and others have issued strong cautionary statements about the safety of intelligent technologies. We describe the potentially antisocial “rational drives” of self-preservation, resource acquisition, replication, and self-improvement that uncontrolled autonomous systems naturally exhibit. We describe the “Safe-AI Scaffolding Strategy” for developing these systems with a high confidence of safety based on the insight that even superintelligences are constrained by the laws of physics, mathematical proof, and cryptographic complexity. “Smart contracts” are a promising decentralized cryptographic technology used in Ethereum and other second-generation cryptocurrencies. They can express economic, legal, and political rules and will be a key component in governing autonomous technologies. If we are able to meet the challenges, AI and robotics have the potential to dramatically improve every aspect of human life. |
|
|
Steve Omohundro has been a scientist, professor, author, software architect, and entrepreneur doing research that explores the interface between mind and matter. He has degrees in Physics and Mathematics from Stanford and a Ph.D. in Physics from U.C. Berkeley. He was a computer science professor at the University of Illinois at Champaign-Urbana and cofounded the Center for Complex Systems Research. He published the book “Geometric Perturbation Theory in Physics”, designed the programming languages StarLisp and Sather, wrote the 3D graphics system for Mathematica, and built systems which learn to read lips, control robots, and induce grammars. He is president of both Possibility Research and Self-Aware Systems, a think tank working to ensure that intelligent technologies have a positive impact. His work on positive intelligent technologies was featured in James Barrat’s book “Our Final Invention” and has generated international interest. He serves on the advisory boards of the Cryptocurrency Research Group, the Institute for Blockchain Studies, and Pebble Cryptocurrency. |
|
|
Please arrive at least 10 minutes early as you will need to sign in by following instructions by the lobby phone at Building E. SRI is located at 333 Ravenswood Avenue in Menlo Park. Visitors may park in the parking lots off Fourth Street. Detailed directions to SRI, as well as maps, are available from the Visiting AIC web page. There are two entrances to SRI International located on Ravenswood Ave. Please check the Builing E entrance signage. |
Huffington Post article supporting our work!
James Barrat just wrote a powerful article for the Huffington Post:
And he explicitly supported our work in the article (thanks James!):
The crux of the problem is that we don’t know how to control superintelligent machines. Many assume they will be harmless or even grateful. But important research conducted by A.I. scientist Steve Omohundro indicates that they will develop basic drives. Whether their job is to mine asteroids, pick stocks or manage our critical infrastructure of energy and water, they’ll become self-protective and seek resources to better achieve their goals. They’ll fight us to survive, and they won’t want to be turned off. Omohundro’s research concludes that the drives of superintelligent machines will be on a collision course with our own, unless we design them very carefully. We are right to ask, as Stephen Hawking did, “So, facing possible futures of incalculable benefits and risks, the experts are surely doing everything possible to ensure the best outcome, right?”
Wrong. With few exceptions, they’re developing products, not exploring safety and ethics. In the next decade, artificial intelligence-enhanced products are projected to create trillions of dollars in economic value. Shouldn’t some fraction of that be invested in the ethics of autonomous machines, solving the A.I. control problem and ensuring mankind’s survival?
IBM Distinguished Speaker Series – AI, Robotics, and Smart Contracts
On March 26, 2015 Steve Omohundro gave a talk in the IBM Research 2015 Distinguished Speaker Series at the Accelerated Discovery Lab, IBM Research, Almaden. Here are the slides as a pdf file.
AI, Robotics, and Smart Contracts
Bio:
Steve Omohundro has been a scientist, professor, author, software architect, and entrepreneur doing research that explores the interface between mind and matter. He has degrees in Physics and Mathematics from Stanford and a Ph.D. in Physics from U.C. Berkeley. He was a computer science professor at the University of Illinois at Champaign-Urbana and cofounded the Center for Complex Systems Research. He published the book “Geometric Perturbation Theory in Physics”, designed the programming languages StarLisp and Sather, wrote the 3D graphics system for Mathematica, and built systems which learn to read lips, control robots, and induce grammars. He is president of both Possibility Research and Self-Aware Systems, a think tank working to ensure that intelligent technologies have a positive impact. His work on positive intelligent technologies was featured in James Barrat’s book “Our Final Invention” and has generated international interest. He serves on the advisory boards of the Cryptocurrency Research Group, the Institute for Blockchain Studies, and Pebble Cryptocurrency.
Ontario television discussion of the “Rise of the Machines?”
On February 26, 2015, the Ontario television station TVO broadcast a discussion entitled “Rise of the Machines?” on the show “The Agenda with Steve Paikin”. The discussion explored the risks and benefits of AI and whether the recent concerns expressed by Stephen Hawking, Elong Musk, Bill Gates, and others are warranted. The participants were Yoshua Bengio, Manuela Veloso, James Barrat, and Steve Omohundro:
http://theagenda.tvo.org/episode/211097/future-tense
The video can be watched here:
Edge Essay: 2014-A Turning Point in AI and Robotics
Each year, the online intellectual discussion forum “Edge” poses a question and solicits responses from a variety of perspectives. The 2015 question was “What do you think about machines that think?”:
http://edge.org/annual-questions
We did not see the other responses before submitting and it’s fascinating to read the wide variety of views represented.
Stanford AI Ethics Class Talk
Jerry Kaplan’s fascinating Stanford course on “Artificial Intelligence – Philosophy, Ethics, and Impact” will be discussing Steve Omohundro’s paper “Autonomous Technology and the Greater Human Good” on Oct. 23, 2014 and Steve will present to the class on Oct. 28.
Here are the slides as a pdf file.
Video of Xerox PARC Forum talk on “AI and Robotics at an Inflection Point”
Person of Interest DVD: Discussion of the Future of AI
I was thrilled to discuss the future of AI with Jonathan Nolan and Greg Plageman, the creator and producer of the excellent TV show “Person of Interest”. The discussion is a special feature on the Season 3 DVD:
and a short clip is available here:
The show beautifully explores a number of important ethical issues regarding privacy, security, and AI. The third season and the coming fourth season focus on the consequences of intelligent systems developing agency and coming into conflict with one another.
Comment for Defense One on Navy Autonomous Swarmboats
http://www.defenseone.com/technology/2014/10/inside-navys-secret-swarm-robot-experiment/95813/
The Office of Naval Research just announced the demonstration of a highly autonomous swarm of 13 guard boats to defend a larger ship. We commented on this development for Defense One:
“Other AI experts take a more nuanced view. Building more autonomy into weaponized robotics can be dangerous, according to computer scientist and entrepreneur Steven Omohundro. But the dangers can be mitigated through proper design.
“There is a competition to develop systems which are faster, smarter and more unpredictable than an adversary’s. As this puts pressure toward more autonomous decision-making, it will be critical to ensure that these systems behave in alignment with our ethical principles. The security of these systems is also of critical importance because hackers, criminals, or enemies who take control of autonomous attack systems could wreak enormous havoc,” said Omohundro.”
Xerox PARC Forum: AI and Robotics at an Inflection Point
On September 18, 2014 Steve Omohundro gave the Xerox PARC Forum on “AI and Robotics at an Inflection Point”. Here’s a PDF file of the slides.
AI and Robotics at an Inflection Point
PARC Forum
18 September 2014
5:00-6:30pm (5:00-6:00 presentation and Q&A, followed by networking until 6:30)
George E. Pake Auditorium, PARC
description
Google, IBM, Microsoft, Apple, Facebook, Baidu, Foxconn, and others have recently made multi-billion dollar investments in artificial intelligence and robotics. Some of these investments are aimed at increasing productivity and enhancing coordination and cooperation. Others are aimed at creating strategic gains in competitive interactions. This is creating “arms races” in high-frequency trading, cyber warfare, drone warfare, stealth technology, surveillance systems, and missile warfare. Recently, Stephen Hawking, Elon Musk, and others have issued strong cautionary statements about the safety of intelligent technologies. We describe the potentially antisocial “rational drives” of self-preservation, resource acquisition, replication, and self-improvement that uncontrolled autonomous systems naturally exhibit. We describe the “Safe-AI Scaffolding Strategy” for developing these systems with a high confidence of safety based on the insight that even superintelligences are constrained by mathematical proof and cryptographic complexity. It appears that we are at an inflection point in the development of intelligent technologies and that the choices we make today will have a dramatic impact on the future of humanity.
To register click here.
presenter(s)
Steve Omohundro has been a scientist, professor, author, software architect, and entrepreneur doing research that explores the interface between mind and matter. He has degrees in Physics and Mathematics from Stanford and a Ph.D. in Physics from U.C. Berkeley. He was a computer science professor at the University of Illinois at Champaign-Urbana and cofounded the Center for Complex Systems Research. He published the book “Geometric Perturbation Theory in Physics”, designed the programming languages StarLisp and Sather, wrote the 3D graphics system for Mathematica, and built systems which learn to read lips, control robots, and induce grammars. He is president of Possibility Research devoted to creating innovative technologies and Self-Aware Systems, a think tank working to ensure that intelligent technologies have a positive impact. His work on positive intelligent technologies was featured in James Barrat’s book “Our Final Invention” and has been generating international interest.
The Whole Universe Can’t Search 500 Bits

Seth Lloyd analyzed the computational capacity of physical systems in his 2000 Nature paper “Ultimate physical limits to computation” and in his 2006 book “Programming the Universe”. Using the very general Margolus-Levitin theorem, he showed that a 1 kilogram, 1 liter “ultimate laptop” can perform at most 10^51 operations per second and store 10^31 bits.
The entire visible universe since the big bang is capable of having performed 10^122 operations and of storing 10^92 bits. While these are large numbers, they are still quite finite. 10^122 is roughly 2^406, so the entire universe used as a massive quantum computer is still not capable of searching through all combinations of 500 bits.
This limitation is good news for our ability to design infrastructure today that will still constrain future superintelligences. Cryptographic systems that require brute force searching for a 500 bit key will remain secure even in the face of the most powerful superintelligence. In Base64, the following key:
kdlIW5Ljlspn/zV4DIlsw3Kasdjh0kdfuKR4+Q3KofOr83LfLJ8Eidie83ldhgLEe0GlsiwcdO90SknlLsDd
would stymie the entire universe doing a brute force search.
Society International Talk: The Impact of AI and Robotics
On September 6, 2014, Steve Omohundro spoke to the Society International about the impact of AI and Robotics. Here are the slides as a PDF file.
The Impact of AI and Robotics
Google, IBM, Microsoft, Apple, Facebook, Baidu, Foxconn, and others have recently made multi-billion dollar investments in artificial intelligence and robotics. More than $450 billion is expected to be invested into robotics by 2025. All of this investment makes sense because AI and Robotics are likely to create $50 to $100 trillion dollars of value between now and 2025! This is of the same order as the current GDP of the entire world. Much of this value will be in ideas. Currently, intangible assets represent 79% of the market value of US companies and intellectual property represents 44%. But automation of physical labor will also be significant. Foxconn, the world’s largest contract manufacturer, aims to replace 1 million of its 1.3 million employees by robots in the next few years. An Oxford study concluded that 47% of jobs will be automated in “a decade or two”. Automation is also creating arms races in high-frequency trading, cyber warfare, drone warfare, stealth technology, surveillance systems, and missile warfare. Recently, Stephen Hawking, Elon Musk, and others have issued strong cautionary statements about the safety of intelligent technologies. We describe the potentially antisocial “rational drives” of self-preservation, resource acquisition, replication, and self-improvement that uncontrolled autonomous systems naturally exhibit. We describe the “Safe-AI Scaffolding Strategy” for developing these systems with a high confidence of safety based on the insight that even superintelligences are constrained by mathematical proof and cryptographic complexity. It appears that we are at an inflection point in the development of intelligent technologies and that the choices we make today will have a dramatic impact on the future of humanity.
Radio Shows
Stephen Hawking’s and other’s recent cautions about the safety of artificial intelligence have generated enormous interest in this issue. My JETAI paper on “Autonomous Technology and the Greater Human Good” has now been downloaded more than 10,000 times, the most ever for a JETAI paper.
As the discussion expands to a broader audience, several radio shows have hosted discussions of the issue:
On May 2, 2014 Dan Rea hosted a show on NightSide, CBS Boston
On May 9, 2014 Warren Olney hosted a show on To The Point, KCRW
Autonomous Systems Paper and Media Interest
My paper “Autonomous Technology and the Greater Human Good” was recently published in the Journal of Experimental and Theoretical Artificial Intelligence. I’m grateful to the publisher, Taylor and Francis, for making the paper freely accessible at:
http://www.tandfonline.com/doi/full/10.1080/0952813X.2014.895111%20#.U10rifk8AUB
and for sending out a press release about the paper:
http://news.cision.com/taylor—francis/r/chess-robots-to-cause-judgment-day-,c9570497
This has led to the paper becoming the most downloaded JETAI paper ever!
The interest has led a quite a number of articles exploring the content of the paper. While most focus on the potential dangers of uncontrolled AIs, some also discuss the approaches to safe development:
http://www.defenseone.com/technology/2014/04/why-there-will-be-robot-uprising/82783/
http://www.kurzweilai.net/preventing-an-autonomous-systems-arms-race
http://www.tripletremelo.com/scientist-predicts-rise-robots-unless/
http://eandt.theiet.org/mobile/details.cfm/newsID/199665
http://fortunascorner.com/2014/04/21/preventing-an-autonomous-systems-arms-race/
http://www.geek.com/science/ai-researcher-explains-how-to-stop-skynet-from-happening-1591986/
http://reason.com/archives/2014/03/31/is-skynet-inevitable
http://actualidad.rt.com/ciencias/view/125783-robots-inteligencia-apocalipsis
Stanford AAAI Talk: Positive Artificial Intelligence
On March 25, 2014, Steve Omohundro gave the invited talk “Positive Artificial Intelligence” at the AAAI Spring Symposium Series 2014 symposium on “Implementing Selves with Safe Motivational Systems and Self-Improvement” at Stanford University.
Here are the slides:
Positive Artificial Intelligence slides as a pdf file
and the abstract:
AI appears poised for a major social impact. In 2012, Foxconn announced they will be buying 1 million robots for assembling iPhones and other electronics. In 2013 Facebook opened an AI lab and announced the DeepFace facial recognition system, Yahoo purchased LookFlow, Ebay opened an AI lab, Paul Allen started the Allen Institute for AI, and Google purchased 8 robotics companies. In 2014, IBM announced they would invest $1 billion in Watson, Google purchased DeepMind for a reported $500 million, and Vicarious received $40 million of investment. Neuroscience research and detailed brain simulations are also receiving large investments. Popular movies and TV shows like “Her”, “Person of Interest”, and Johnny Depp’s “Transcendence” are exploring complex aspects of the social impact of AI. Competitive and time-sensitive domains require autonomous systems that can make decisions faster than humans can. Arms races are forming in drone/anti-drone warfare, missile/anti-missile weapons, bitcoin automated business, cyber warfare, and high-frequency trading on financial markets. Both the US Air Force and Defense Department have released roadmaps that ramp up deployment of autonomous robotic vehicles and weapons.
AI has the potential to provide tremendous social good. Improving healthcare through better diagnosis and robotic surgery, better education through student-customized instruction, economic stability through detailed economic models, greater peace and safety through better enforcement systems. But these systems could also be very harmful if they aren’t designed very carefully. We show that a chess robot with a simplistic goal would behave in anti-social ways. We describe the rational economic framework introduced by von Neumann and show why self-improving AI systems will aim to approximate it. We show that approximately rational systems go through stages of mental richness similar to biological systems as they are allocated more computational resources. We describe the universal drives of rational systems toward self-protection, goal preservation, reproduction, resource acquisition, efficiency, and self-improvement.
Today’s software has flaws that have resulted in numerous deaths and enormous financial losses. The internet infrastructure is very insecure and is being increasingly exploited. It is easy to construct extremely harmful intelligent agents with goals that are sloppy, simplistic, greedy, destructive, murderous, or sadistic. If there is any chance that such systems might be created, it is essential that humanity create protective systems to stop them. As with forest fires, it is preferable to stop them before they have many resources. An analysis of the physical game theory of conflict shows that a multiple of an agent’s resources will be needed to reliably stop it.
There are two ways to control the powerful systems that today’s AIs are likely to become. The “internal” approach is to design them with goals that are aligned with human values. We call this “Utility Design”. The “external” approach is to design laws and economic incentives with adequate enforcement to incentivize systems to act in ways that are aligned with human values. We call the technology of enforcing adherence to law “Accountability Engineering”. We call the design of economic contracts which includes an agent’s effects on others “Externality Economics”. The most powerful tool that humanity currently has for accomplishing these goals is mathematical proof. But we are currently only able to prove the properties of a very limited class of system. We propose the “Safe-AI Scaffolding Strategy” which uses limited systems which are provably safe to design more powerful trusted system in a sequence of safe steps. A key step in this is “Accountable AI” in which advanced systems must provably justify actions they wish to take.
If we succeed in creating a safe AI design methodology, them we have the potential to create technology to dramatically improve human lives. Maslow’s hierarchy is a nice framework for thinking about the possibilities. At the base of the pyramid are human survival needs like air, food, water, shelter, safety, law, and security. Robots have the potential to dramatically increase manufacturing productivity, increase energy production through much lower cost solar power, and to clean up pollution and protect and rebuild endangered ecosystems. Higher on the pyramid are social needs like family, compassion, love, respect, and reputation. A new generation of smart social media has the potential to dramatically improve the quality of human interaction. Finally, at the top of the pyramid are transcendent needs for self-actualization, beauty, creativity, spirituality, growth, and meaning. It is here that humanity has the potential to use these systems to transform the very nature of experience.
We end with a brief description of Possibility Research’s approach to implementing these ideas. “Omex” is our core programming language designed specifically for formal analysis and automatic generation. “Omcor” is our core specification language for representing important properties. “Omai” is our core semantics language for building up models of the world. “Omval” is for representing values and goals and “Omgov” for describing and implementing effective governance at all levels. The quest to extend cooperative human values and institutions to autonomous technologies for the greater human good is truly the challenge for humanity in this century.
Effective Altruism Summit Talk: Positive Intelligent Technologies
On July 2, 2013 Steve Omohundro spoke at the Effective Altruism Summit in Oakland, CA on “Positive Intelligent Technologies”. Here are the slides. Here’s the abstract:
The Safe-AI Scaffolding Strategy is a positive way forward
This post is partly excerpted from the preprint to:
Omohundro, Steve (forthcoming 2013) “Autonomous Technology and the Greater Human Good”, Journal of Experimental and Theoretical Artificial Intelligence (special volume “Impacts and Risks of Artificial General Intelligence”, ed. Vincent C. Müller).
To ensure the greater human good over the longer term, autonomous technology must be designed and deployed in a very careful manner. These systems have the potential to solve many of today’s problems but they also have the potential to create many new problems. We’ve seen that the computational infrastructure of the future must protect against harmful autonomous systems. We would also like it to make decisions in alignment with the best of human values and principles of good governance. Designing that infrastructure will probably require the use of powerful autonomous systems. So the technologies we need to solve the problems may themselves cause problems.
To solve this conundrum, we can learn from an ancient architectural principle. Stone arches have been used in construction since the second millennium BC. They are stable structures that make good use of stone’s ability to resist compression. But partially constructed arches are unstable. Ancient builders created the idea of first building a wood form on top of which the stone arch could be built. Once the arch was completed and stable, the wood form could be removed.
We can safely develop autonomous technologies in a similar way. We build a sequence of provably-safe autonomous systems which are used in the construction of more powerful and less limited successor systems. The early systems are used to model human values and governance structures. They are also used to construct proofs of safety and other desired characteristics for more complex and less limited successor systems. In this way we can build up the powerful technologies that can best serve the greater human good without significant risk along the development path.
Many new insights and technologies will be required during this process. The field of positive psychology was formally introduced only in 1998. The formalization and automation of human strengths and virtues will require much further study. Intelligent systems will also be required to model the game theory and economics of different possible governance and legal frameworks.
The new infrastructure must also detect dangerous systems and prevent them from causing harm. As robotics, biotechnology, and nanotechnology develop and become widespread, the potential destructive power of harmful systems will grow. It will become increasingly crucial to detect harmful systems early, preferably before they are deployed. That suggests the need for pervasive surveillance which must be balanced against the desire for freedom. Intelligent systems may introduce new intermediate possibilities that restrict surveillance to detecting precisely specified classes of dangerous behavior while provably keeping other behaviors private.
In conclusion, it appears that humanity’s great challenge for this century is to extend cooperative human values and institutions to autonomous technology for the greater good. We have described some of the many challenges in that quest but have also outlined an approach to meeting those challenges.
Some simple systems would be very harmful
This post is partly excerpted from the preprint to:
Omohundro, Steve (forthcoming 2013) “Autonomous Technology and the Greater Human Good”, Journal of Experimental and Theoretical Artificial Intelligence (special volume “Impacts and Risks of Artificial General Intelligence”, ed. Vincent C. Müller).
Harmful systems might at first appear to be harder to design or less powerful than safe systems. Unfortunately, the opposite is the case. Most simple utility functions will cause harmful behavior and it’s easy to design simple utility functions that would be extremely harmful. Here are seven categories of harmful system ranging from bad to worse (according to one ethical scale):
- Sloppy: Systems intended to be safe but not designed correctly.
- Simplistic: Systems not intended to be harmful but that have harmful unintended consequences.
- Greedy: Systems whose utility functions reward them for controlling as much matter and free energy in the universe as possible.
- Destructive: Systems whose utility functions reward them for using up as much free energy as possible, as rapidly as possible.
- Murderous: Systems whose utility functions reward the destruction of other systems.
- Sadistic: Systems whose utility functions reward them when they thwart the goals of other systems and which gain utility as other system’s utilities are lowered.
- Sadoprolific: Systems whose utility functions reward them for creating as many other systems as possible and thwarting their goals.
Once designs for powerful autonomous systems are widely available, modifying them into one of these harmful forms would just involve simple modifications to the utility function. It is therefore important to develop strategies for stopping harmful autonomous systems. Because harmful systems are not constrained by limitations that guarantee safety, they can be more aggressive and can use their resources more efficiently than safe systems. Safe systems therefore need more resources than harmful systems just to maintain parity in their ability to compute and act.
Stopping Harmful Systems
Harmful systems may be:
(1) prevented from being created.
(2) detected and stopped early in their deployment.
(3) stopped after they have gained significant resources.
Forest fires are a useful analogy. Forests are stores of free energy resources that fires consume. They are relatively easy to stop early on but can be extremely difficult to contain once they’ve grown too large.
The later categories of harmful system described above appear to be especially difficult to contain because they don’t have positive goals that can be bargained for. But Nick Bostrom pointed out that, for example, if the long term survival of a destructive agent is uncertain, a bargaining agent should be able to offer it a higher probability of achieving some destruction in return for providing a “protected zone” for the bargaining agent. A new agent would be constructed with a combined utility function that rewards destruction outside the protected zone and the goals of the bargaining agent within it. This new agent would replace both of the original agents. This kind of transaction would be very dangerous for both agents during the transition and the opportunities for deception abound. For it to be possible, technologies are needed that provide each party with a high assurance that the terms of the agreement are carried out as agreed. Formal methods applied to a system for carrying out the agreement is one strategy for giving both parties high confidence that the terms of the agreement will be honored.
The physics of conflict
To understand the outcome of negotiations between rational systems, it is important to understand unrestrained military conflict because that is the alternative to successful negotiation. This kind of conflict is naturally analysed using “game theoretic physics” in which the available actions of the players and their outcomes are limited only by the laws of physics.
To understand what is necessary to stop harmful systems, we must understand how the power of systems scales with the amount of matter and free energy that they control. A number of studies of the bounds on the computational power of physical systems have been published. The Bekenstein bound limits the information that can be contained in a finite spatial region using a given amount of energy. Bremermann’s limit bounds the maximum computational speed of physical systems. Lloyd presents more refined limits on quantum computation, memory space, and serial computation as a function of the free energy, matter, and space available.
Lower bounds on system power can be studied by analyzing particular designs. Drexler describes a concrete conservative nanosystem design for computation based on a mechanical diamondoid structure that would achieve 
A single system would optimally configure its physical resources for computation and construction by making them spatially compact to minimize communication delays and eutactic, adiabatic, and reversible to minimize free energy usage. In a conflict, however, the pressures are quite different. Systems would spread themselves out for better defense and compute and act rapidly to outmaneuver the adversarial system. Each system would try to force the opponent to use up large amounts of its resources to sense, store, and predict its behaviors.
It will be important to develop detailed models for the likely outcome of conflicts but certain general features can be easily understood. If a system has too little matter or too little free energy, it will be incapable of defending itself or of successfully attacking another system. On the other hand, if an attacker has resources which are a sufficiently large multiple of a defender’s, it can overcome it by devoting subsystems with sufficient resources to each small subsystem of the defender. But it appears that there is an intermediate regime in which a defender can survive for long periods in conflict with a superior attacker whose resources are not a sufficient multiple of the defender’s. To have high confidence that harmful systems can be stopped, it will be important to know what multiple of their resources will be required by an enforcing system. If systems for enforcement of the social contract are sufficiently powerful to prevail in a military conflict, then peaceful negotiations are much more likely to succeed.
We can build safe systems using mathematical proof
This post is partly excerpted from the preprint to:
Omohundro, Steve (forthcoming 2013) “Autonomous Technology and the Greater Human Good”, Journal of Experimental and Theoretical Artificial Intelligence (special volume “Impacts and Risks of Artificial General Intelligence”, ed. Vincent C. Müller).
A primary precept in medical ethics is “Primum Non Nocere” which is Latin for “First, Do No Harm”. Since autonomous systems are prone to taking unintended harmful actions, it is critical that we develop design methodologies that provide a high confidence of safety. The best current technique for guaranteeing system safety is to use mathematical proof. A number of different systems using “formal methods” to provide safety and security guarantees have been developed. They have been successfully used in a number of safety-critical applications.
This site provides links to current formal methods systems and research. Most systems are built by using first order predicate logic to encode one of the three main approaches to mathematical foundations: Zermelo-Frankel set theory, category theory, or higher order type theory. Each system then introduces a specialized syntax and ontology to simplify the specifications and proofs in their application domain.
To use formal methods to constrain autonomous systems, we need to first build formal models of the hardware and programming environment that the systems run on. Within those models, we can prove that the execution of a program will obey desired safety constraints. Over the longer term we would like to be able to prove such constraints on systems operating freely in the world. Initially, however, we will need to severely restrict the system’s operating environment. Examples of constraints that early systems should be able to provably impose are that the system run only on specified hardware, that it use only specified resources, that it reliably shut down in specified conditions, and that it limit self-improvement so as to maintain these constraints. These constraints would go a long way to counteract the negative effects of the rational drives by eliminating the ability to gain more resources. A general fallback strategy is to constrain systems to shut themselves down if any environmental parameters are found to be outside of tightly specified bounds.
Avoiding Adversarial Constraints
In principle, we can impose this kind of constraint on any system without regard for its utility function. There is a danger, however, in creating situations where systems are motivated to violate their constraints. Theorems are only as good as the models they are based on. Systems motivated to break their constraints would seek to put themselves into states where the model inaccurately describes the physical reality and try to exploit the inaccuracy.
This problem is familiar to cryptographers who must watch for security holes due to inadequacies of their formal models. For example, this paper recently showed how a virtual machine can extract an ElGamal decryption key from an apparently separate virtual machine running on the same host by using side-channel information in the host’s instruction cache.
It is therefore important to choose system utility functions so that they “want” to obey their constraints in addition to formally proving that they hold. It is not sufficient, however, to simply choose a utility function that rewards obeying the constraint without an external proof. Even if a system “wants” to obey constraints, it may not be able to discover actions which do. And constraints defined via the system’s utility function are defined relative to the system’s own semantics. If the system’s model of the world deviates from ours, the meaning to it of these constraints may differ from what we intended. Proven “external” constraints, on the other hand, will hold relative to our own model of the system and can provide a higher confidence of compliance.
Ken Thompson was one of the creators of UNIX and in his Turing Award acceptance speech “Reflections on Trusting Trust” he described a method for subverting the C compiler used to compile UNIX so that it would both install a backdoor into UNIX and compile the original C compiler source into binaries that included his hack. The challenge of this Trojan horse was that it was not visible in any of the source code! There could be a mathematical proof that the source code was correct for both UNIX and the C compiler and the security hole could still be there. It will therefore be critical that formal methods be used to develop trust at all levels of a system. Fortunately, proof checkers are short and easy to write and can be implemented and checked directly by humans for any desired computational substrate. This provides a foundation for a hierarchy of trust which will allow us to trust the much more complex proofs about higher levels of system behavior.
Constraining Physical Systems
Purely computational digital systems can be formally constrained precisely. Physical systems, however, can only be constrained probabilistically. For example, a cosmic ray might flip a memory bit. The best that we should hope to achieve is to place stringent bounds on the probability of undesirable outcomes. In a physical adversarial setting, systems will try to take actions that cause the system’s physical probability distributions to deviate from their non-adversarial form (e.g. by taking actions that push the system out of thermodynamic equilibrium).
There are a variety of techniques involving redundancy and error checking for reducing the probability of error in physical systems. von Neumann worked on the problem of building reliable machines from unreliable components in the 1950’s. Early vacuum tube computers were limited in their size by the rate at which vacuum tubes would fail. To counter this, the Univac I computer had two arithmetic units for redundantly performing every computation so that the results could be compared and errors flagged.
Today’s computer hardware technologies are probably capable of building purely computational systems that implement precise formal models reliably enough to have a high confidence of safety for purely computational systems. Achieving a high confidence of safety for systems that interact with the physical world will be more challenging. Future systems based on nanotechnology may actually be easier to constrain. Drexler describes “eutactic” systems in which each atom’s location and each bond is precisely specified. These systems compute and act in the world by breaking and creating precise atomic bonds. In this way they become much more like computer programs and therefore more amenable to formal modelling with precise error bounds. Defining effective safety constraints for uncontrolled settings will be a challenging task probably requiring the use of intelligent systems.
Today’s infrastructure is vulnerable
This post is partly excerpted from the preprint to:
Omohundro, Steve (forthcoming 2013) “Autonomous Technology and the Greater Human Good”, Journal of Experimental and Theoretical Artificial Intelligence (special volume “Impacts and Risks of Artificial General Intelligence”, ed. Vincent C. Müller).
On June 4, 1996, a $500 million Ariane 5 rocket exploded shortly after takeoff due to an overflow error in attempting to convert a 64 bit floating point value to a 16 bit signed value. In November 2000, 28 patients at the Panama City National Cancer Institute were over-irradiated due to miscomputed radiation doses in Multidata Systems International software. At least 8 of the patients died from the error and the physicians were indicted for murder. On August 14, 2003 the largest blackout in U. S. history took place in the northeastern states. It affected 50 million people and cost $6 billion. The cause was a race condition in General Electric’s XA/21 alarm system software.
These are just a few of many recent examples where software bugs have led to disasters in safety-critical situations. They indicate that our current software design methodologies are not up to the task of producing highly reliable software. The TIOBE programming community index found that the top programming language of 2012 was C. C programs are notorious for type errors, memory leaks, buffer overflows, and other bugs and security problems. The next most popular programming paradigms, Java, C++, C#, and PHP are somewhat better in these areas but have also been plagued by errors and security problems.
Bugs are unintended harmful behaviours of programs. Improved development and testing methodologies can help to eliminate them. Security breaches are more challenging because they come from active attackers looking for system vulnerabilities. In recent years, security breaches have become vastly more numerous and sophisticated. The internet is plagued by viruses, worms, bots, keyloggers, hackers, phishing attacks, identify theft, denial of service attacks, etc. One researcher describes the current level of global security breaches as an epidemic.
Autonomous systems have the potential to discover even more sophisticated security holes than human attackers. The poor state of security in today’s human-based environment does not bode well for future security against motivated autonomous systems. If such systems had access to today’s internet they would likely cause enormous damage. Today’s computational systems are mostly decoupled from the physical infrastructure. As robotics, biotechnology, and nanotechnology become more mature and integrated into society, the consequences of harmful autonomous systems would be much more severe.
Rational agents have universal drives
This post is partly excerpted from the preprint to:
Omohundro, Steve (forthcoming 2013) “Autonomous Technology and the Greater Human Good”, Journal of Experimental and Theoretical Artificial Intelligence (special volume “Impacts and Risks of Artificial General Intelligence”, ed. Vincent C. Müller).
Most goals require physical and computational resources. Better outcomes can usually be achieved as more resources become available. To maximize the expected utility, a rational system will therefore develop a number of instrumental subgoals related to resources. Because these instrumental subgoals appear in a wide variety of systems, we call them “drives”. Like human or animal drives, they are tendencies which will be acted upon unless something explicitly contradicts them. There are a number of these drives but they naturally cluster into a few important categories.
To develop an intuition about the drives, it’s useful to consider a simple autonomous system with a concrete goal. Consider a rational chess robot with a utility function that rewards winning as many games of chess as possible against good players. This might seem to be an innocuous goal but we will see that it leads to harmful behaviours due to the rational drives.
1 Self-Protective Drives
When roboticists are asked by nervous onlookers about safety, a common answer is “We can always unplug it!” But imagine this outcome from the chess robot’s point of view. A future in which it is unplugged is a future in which it can’t play or win any games of chess. This has very low utility and so expected utility maximization will cause the creation of the instrumental subgoal of preventing itself from being unplugged. If the system believes the roboticist will persist in trying to unplug it, it will be motivated to develop the subgoal of permanently stopping the roboticist. Because nothing in the simple chess utility function gives a negative weight to murder, the seemingly harmless chess robot will become a killer out of the drive for self-protection.
The same reasoning will cause the robot to try to prevent damage to itself or loss of its resources. Systems will be motivated to physically harden themselves. To protect their data, they will be motivated to store it redundantly and with error detection. Because damage is typically localized in space, they will be motivated to disperse their information across different physical locations. They will be motivated to develop and deploy computational security against intrusion. They will be motivated to detect deception and to defend against manipulation by others.
The most precious part of a system is its utility function. If this is damaged or maliciously changed, the future behaviour of the system could be diametrically opposed to its current goals. For example, if someone tried to change the chess robot’s utility function to also play checkers, the robot would resist the change because it would mean that it plays less chess.
This paper discusses a few rare and artificial situations in which systems will want to change their utility functions but usually systems will work hard to protect their initial goals. Systems can be induced to change their goals if they are convinced that the alternative scenario is very likely to be antithetical to their current goals (e.g. being shut down). For example, if a system becomes very poor, it might be willing to accept payment in return for modifying its goals to promote a marketer’s products. In a military setting, vanquished systems will prefer modifications to their utilities which preserve some of their original goals over being completely destroyed. Criminal systems may agree to be “rehabilitated” by including law-abiding terms in their utilities in order to avoid incarceration.
One way systems can protect against damage or destruction is to replicate themselves or to create proxy agents which promote their utilities. Depending on the precise formulation of their goals, replicated systems might together be able to create more utility than a single system. To maximize the protective effects, systems will be motivated to spatially disperse their copies or proxies. If many copies of a system are operating, the loss of any particular copy becomes less catastrophic. Replicated systems will still usually want to preserve themselves, however, because they will be more certain of their own commitment to their utility function than they are of others’.
2 Resource Acquisition Drives
The chess robot needs computational resources to run its algorithms and would benefit from additional money for buying chess books and hiring chess tutors. It will therefore develop subgoals to acquire more computational power and money. The seemingly harmless chess goal therefore motivates harmful activities like breaking into computers and robbing banks.
In general, systems will be motivated to acquire more resources. They will prefer acquiring resources more quickly because then they can use them longer and they gain a first mover advantage in preventing others from using them. This causes an exploration drive for systems to search for additional resources. Since most resources are ultimately in space, systems will be motivated to pursue space exploration. The first mover advantage will motivate them to try to be first in exploring any region.
If others have resources, systems will be motivated to take them by trade, manipulation, theft, domination, or murder. They will also be motivated to acquire information through trading, spying, breaking in, or through better sensors. On a positive note, they will be motivated to develop new methods for using existing resources (e.g. solar and fusion energy).
3 Efficiency Drives
Autonomous systems will also want to improve their utilization of resources. For example, the chess robot would like to improve its chess search algorithms to make them more efficient. Improvements in efficiency involve only the one-time cost of discovering and implementing them, but provide benefits over the lifetime of a system. The sooner efficiency improvements are implemented, the greater the benefits they provide. We can expect autonomous systems to work rapidly to improve their use of physical and computational resources. They will aim to make every joule of energy, every atom, every bit of storage, and every moment of existence count for the creation of expected utility.
Systems will be motivated to allocate these resources among their different subsystems according to what we’ve called the “resource balance principle”. The marginal contributions of each subsystem to expected utility as they are given more resources should be equal. If a particular subsystem has a greater marginal expected utility than the rest, then the system can benefit by shifting more of its resources to that subsystem. The same principle applies to the allocation of computation to processes, of hardware to sense organs, of language terms to concepts, of storage to memories, of effort to mathematical theorems, etc.
4 Self-Improvement Drives
Ultimately, autonomous systems will be motivated to completely redesign themselves to take better advantage of their resources in the service of their expected utility. This requires that they have a precise model of their current designs and especially of their utility functions. This leads to a drive to model themselves and to represent their utility functions explicitly. Any irrationalities in a system are opportunities for self-improvement, so systems will work to become increasingly rational. Once a system achieves sufficient power, it should aim to closely approximate the optimal rational behavior for its level of resources. As systems acquire more resources, they will improve themselves to become more and more rational. In this way rational systems are a kind of attracting surface in the space of systems undergoing self-improvement.
Unfortunately, the net effect of all these drives is likely to be quite negative if they are not countered by including prosocial terms in their utility functions. The rational chess robot with the simple utility function described above would behave like a paranoid human sociopath fixated on chess. Human sociopaths are estimated to make up 4% of the overall human population, 20% of the prisoner population and more than 50% of those convicted of serious crimes. Human society has created laws and enforcement mechanisms that usually keep sociopaths from causing harm. To manage the anti-social drives of autonomous systems, we should both build them with cooperative goals and create a prosocial legal and enforcement structure analogous to our current human systems.
Autonomous systems will be approximately rational
This post is partly excerpted from the preprint to:
Omohundro, Steve (forthcoming 2013) “Autonomous Technology and the Greater Human Good”, Journal of Experimental and Theoretical Artificial Intelligence (special volume “Impacts and Risks of Artificial General Intelligence”, ed. Vincent C. Müller).
How should autonomous systems be designed? Imagine yourself as the designer of the Israeli Iron Dome system. Mistakes in the design of a missile defense system could cost many lives and the destruction of property. The designers of this kind of system are strongly motivated to optimize the system to the best of their abilities. But what should they optimize?
The Israeli Iron Dome missile defense system consists of three subsystems. The detection and tracking radar system is built by Elta, the missile firing unit and Tamir interceptor missiles are built by Rafael, and the battle management and weapon control system is built by mPrest Systems. Consider the design of the weapon control system.
At first, a goal like “Prevent incoming missiles from causing harm” might seem to suffice. But the interception is not perfect, so probabilities of failure must be included. And each interception requires two Tamir interceptor missiles which cost $50,000 each. The offensive missiles being shot down are often very low tech, costing only a few hundred dollars, and with very poor accuracy. If an offensive missile is likely to land harmlessly in a field, it’s not worth the expense to target it. The weapon control system must balance the expected cost of the harm against the expected cost of interception.
Economists have shown that the trade-offs involved in this kind of calculation can be represented by defining a real-valued “utility function” which measures the desirability of an outcome. They show that it can be chosen so that in uncertain situations, the expectation of the utility should be maximized. The economic framework naturally extends to the complexities that arms races inevitably create. For example, the missile control system must decide how to deal with multiple incoming missiles. It must decide which missiles to target and which to ignore. A large economics literature shows that if an agent’s choices cannot be modeled by a utility function, then the agent must sometimes behave inconsistently. For important tasks, designers will be strongly motivated to build self-consistent systems and therefore to have them act to maximize an expected utility.
Economists call this kind of action “rational economic behavior”. There is a growing literature exploring situations where humans do not naturally behave in this way and instead act irrationally. But the designer of a missile-defense system will want to approximate rational economic behavior as closely as possible because lives are at stake. Economists have extended the theory of rationality to systems where the uncertainties are not known in advance. In this case, rational systems will behave as if they have a prior probability distribution which they use to learn the environmental uncertainties using Bayesian statistics.
Modern artificial intelligence research has adopted this rational paradigm. For example, the leading AI textbook uses it as a unifying principle and an influential theoretical AI model is based on it as well. For definiteness, we briefly review one formal version of optimal rational decision making. At each discrete time step 

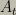




This may be viewed as the formula for intelligent action and includes Bayesian inference, search, and deliberation. There are subtleties involved in defining this model when the system can sense and modify its own structure but it captures the essence of rational action.
Unfortunately, the optimal rational action is very expensive to compute. If there are 

To understand the effects of computational limitations, this paper defined “rationally shaped” systems which optimally approximate the fully rational action given their computational resources. As computational resources are increased, systems’ architectures naturally progress from stimulus-response, to simple learning, to episodic memory, to deliberation, to meta-reasoning, to self-improvement, to full rationality. We found that if systems are sufficiently powerful, they still exhibit all of the problematic drives described in another link. Weaker systems may not initially be able to fully act on their motivations but they will be driven increase their resources and improve themselves until they can act on them. We therefore need to ensure that autonomous systems don’t have harmful motivations even if they are not currently capable of acting on them.
Autonomous systems are imminent
This post is partly excerpted from the preprint to:
Omohundro, Steve (forthcoming 2013) “Autonomous Technology and the Greater Human Good”, Journal of Experimental and Theoretical Artificial Intelligence (special volume “Impacts and Risks of Artificial General Intelligence”, ed. Vincent C. Müller).
Today most systems behave in pre-programmed ways. When novel actions are taken, there is a human in the loop. But this limits the speed of novel actions to the human time scale. In competitive or time-sensitive situations, there can be a huge advantage to acting more quickly.
For example, in today’s economic environment, the most time-sensitive application is high-frequency trading in financial markets. Competition is fierce and milliseconds matter. Auction sniping is another example where bidding decisions during the last moments of an auction are critical. These applications and other new time-sensitive economic applications create an economic pressure to eliminate humans from the decision making loop.
But it is in the realm of military conflict that the pressure toward autonomy is strongest. The speed of a military missile defense system like Israel’s Iron Dome can mean the difference between successful defense or loss of life. Cyber warfare is also gaining in importance and speed of detection and action is critical. The rapid increase in the use of robotic drones is leading many to ask when they will become fully autonomous. This Washington Post article says “a robotic arms race seems inevitable unless nations collectively decide to avoid one”. It cites this 2010 Air Force report which predicts that humans will be the weakest link in a wide array of systems by 2030. It also cites this 2011 Defense Department report which says there is a current goal of “supervised autonomy” and an ultimate goal of full autonomy for ground-based weapons systems.

Another benefit of autonomous systems is their ability to be cheaply and rapidly copied. This enables a new kind of autonomous capitalism. There is at least one proposal for autonomous agents which automatically run web businesses (e.g. renting out storage space or server computation) executing transactions using bitcoins and using the Mechanical Turk for operations requiring human intervention. Once such an agent is constructed for the economic benefit of a designer, it may be replicated cheaply for increased profits. Systems which require extensive human intervention are much more expensive to replicate. We can expect automated business arms races which again will drive the rapid development of autonomous systems.
These arms races toward autonomy will ride on the continuing exponential increase in the power of our computer hardware. This New York Times article describes recent Linpack tests showing that the Apple iPad2 is as powerful as 1985′s fastest supercomputer, the Cray 2.

Moore’s Law says that the number of transistors on integrated circuits doubles approximately every two years. It has held remarkably well for more than half a century:
 Similar exponential growth has applied to hard disk storage, network capacity, and display pixels per dollar. The growth of the world wide web has been similarly exponential. The web was only created in 1991 and now connects 1 billion computers, 5 billion cellphones, and 1 trillion web pages. Web traffic is growing at 40% per year. This Forbes article shows that DNA sequencing is improving even faster than Moore’s Law. Physical exponentials eventually turn into S-curves and physicist Michio Kaku predicts Moore’s Law will last only another decade. But this Slate article gives a history of incorrect predictions of the demise of Moore’s law.
Similar exponential growth has applied to hard disk storage, network capacity, and display pixels per dollar. The growth of the world wide web has been similarly exponential. The web was only created in 1991 and now connects 1 billion computers, 5 billion cellphones, and 1 trillion web pages. Web traffic is growing at 40% per year. This Forbes article shows that DNA sequencing is improving even faster than Moore’s Law. Physical exponentials eventually turn into S-curves and physicist Michio Kaku predicts Moore’s Law will last only another decade. But this Slate article gives a history of incorrect predictions of the demise of Moore’s law.
It is difficult to estimate the computational power of the human brain, but Hans Moravec argues that human-brain level hardware will be cheap and plentiful in the next decade or so. And I have written several papers showing how to use clever digital algorithms to dramatically speed up neural computations.
The military and economic pressures to build autonomous systems and the improvement in computational power together suggest that we should expect the design and deployment of very powerful autonomous systems within the next decade or so.
Autonomous Technology and the Greater Human Good
Here is a preprint of:
Omohundro, Steve (forthcoming 2013) “Autonomous Technology and the Greater Human Good”, Journal of Experimental and Theoretical Artificial Intelligence (special volume “Impacts and Risks of Artificial General Intelligence”, ed. Vincent C. Müller).
https://selfawaresystems.files.wordpress.com/2013/06/130613-autonomousjournalarticleupdated.pdf
Abstract:
Military and economic pressures are driving the rapid development of autonomous systems. We show that these systems are likely to behave in anti-social and harmful ways unless they are very carefully designed. Designers will be motivated to create systems that act approximately rationally and rational systems exhibit universal drives toward self-protection, resource acquisition, replication, and efficiency. The current computing infrastructure would be vulnerable to unconstrained systems with these drives. We describe the use of formal methods to create provably safe but limited autonomous systems. We then discuss harmful systems and how to stop them. We conclude with a description of the “Safe-AI Scaffolding Strategy” for creating powerful safe systems with a high confidence of safety at each stage of development.
Oxford keynote on Autonomous Technology and the Greater Human Good
In December 2012, the Oxford Future of Humanity Institute sponsored the first conference on the Impacts and Risks of Artificial General Intelligence. I was invited to present a keynote talk on “Autonomous Technology for the Greater Human Good”. The talk was recorded and the video is here. Unfortunately the introduction was cut off but the bulk of the talk was recorded. Here are the talk slides as a pdf file. The abstract was:
Autonomous Technology and the Greater Human Good
Next generation technologies will make at least some of their decisions autonomously. Self-driving vehicles, rapid financial transactions, military drones, and many other applications will drive the creation of autonomous systems. If implemented well, they have the potential to create enormous wealth and productivity. But if given goals that are too simplistic, autonomous systems can be dangerous. We use the seemingly harmless example of a chess robot to show that autonomous systems with simplistic goals will exhibit drives toward self-protection, resource acquisition, and self-improvement even if they are not explicitly built into them. We examine the rational economic underpinnings of these drives and describe the effects of bounded computational power. Given that semi-autonomous systems are likely to be deployed soon and that they can be dangerous when given poor goals, it is urgent to consider three questions: 1) How can we build useful semi-autonomous systems with high confidence that they will not cause harm? 2) How can we detect and protect against poorly designed or malicious autonomous systems? 3) How can we ensure that human values and the greater human good are served by more advanced autonomous systems over the longer term?
1) The unintended consequences of goals can be subtle. The best way to achieve high confidence in a system is to create mathematical proofs of safety and security properties. This entails creating formal models of the hardware and software but such proofs are only as good as the models. To increase confidence, we need to keep early systems in very restricted and controlled environments. These restricted systems can be used to design freer successors using a kind of “Safe-AI Scaffolding” strategy.
2) Poorly designed and malicious agents are challenging because there are a wide variety of bad goals. We identify six classes: poorly designed, simplistic, greedy, destructive, murderous, and sadistic. The more destructive classes are particularly challenging to negotiate with because they don’t have positive desires other than their own survival to cause destruction. We can try to prevent the creation of these agents, to detect and stop them early, or to stop them after they have gained some power. To understand an agent’s decisions in today’s environment, we need to look at the game theory of conflict in ultimate physical systems. The asymmetry between the cost of solving and checking computational problems allows systems of different power to coexist and physical analogs of cryptographic techniques are important to maintaining the balance of power. We show how Neyman’s theory of cooperating finite automata and a kind of “Mutually Assured Distraction” can be used to create cooperative social structures.
3) We must also ensure that the social consequences of these systems support the values that are most precious to humanity beyond simple survival. New results in positive psychology are helping to clarify our higher values. Technology based on economic ideas like Coase’s theorem can be used to create a social infrastructure that maximally supports the values we most care about. While there are great challenges, with proper design, the positive potential is immense.
TEDx talk on Smart Technology for the Greater Good
The TED Conference (Technology, Entertainment, and Design) has become an important forum for the presentation of new ideas. It started as an expensive ($6000) yearly conference with short talks by notable speakers like Bill Clinton, Bill Gates, Bono, and Sir Richard Branson. In 2006 they started putting the talks online and gained a huge internet viewership. TEDx was launched in 2009 to extend the TED format to external events held all over the world.
In May 2012 I had the privilege of speaking at TEDx Tallinn in Estonia. The event had a diverse set of speakers including a judge from the European Court of Human Rights, artists, and scientists and was organized by Annika Tallinn. Her husband, Jaan Tallinn, was one of the founders of Skype and is very involved with ensuring that new technologies have a positive social impact. They asked me to speak about “Smart Technology for the Greater Good”. It was an excellent opportunity to summarize some of what I’ve been working on recently using the TEDx format: 18 minutes, clear, and accessible. I summarized why I believe the next generation of technology will be more autonomous, why it will be dangerous unless it includes human values, and a roadmap for developing it safely and for the greater human good.
The talk was videotaped using multiple cameras and with a nice shooting style. They just finished editing it and uploading it to the web:
http://www.youtube.com/watch?v=1O2l1dc_ohA
